How a 2,000-line prompt file became an AI Development Operating System - and what that means for anyone building software today.
There’s a moment every ambitious builder eventually hits.
You’ve been using AI to write code. It’s fast. It’s impressive. Then your project starts to grow - more services, more complexity, more things that need to be consistent across a codebase - and you realize the AI is just winging it alongside you.
Different conventions in different files. Security considerations that appear only when you think to ask. Tests that pass without actually covering much. A general sense that the system is smart but undisciplined.
That was my moment. My entire development workflow had collapsed into a single file: CLAUDE.md.
It started small. Then it grew. Coding standards, architecture decisions, naming rules, CI/CD policies, security requirements, testing mandates, deployment patterns - all crammed into one increasingly unruly document.
Eventually it crossed 2,000 lines.
It worked. But it wasn’t scalable. And more importantly, it was a sign that I’d been thinking about AI-assisted development the wrong way - as a productivity tool rather than an engineering system.
What follows is the journey from that realization to something I now think of as an AI Development Operating System: a structured, governed, multi-agent platform that can take a well-defined idea from requirements to deployable software in days rather than months.
This is not a guide about prompt tricks. It’s about engineering discipline. And it’s written for both the founder who needs to understand what their technical team is building - and the engineer who needs a clear architectural map.
Why This Architecture Exists (And Why You Haven’t Seen It Elsewhere)
Most people building with AI today come from machine learning, data science, or frontend development. They think in models, prompts, and interfaces. That’s not wrong - but it represents one perspective.
The DevOps background was instrumental in seeing what others might miss. Twenty years in infrastructure, distributed systems, and CI/CD platforms - large-scale migrations, production failures debugged at 3 AM, systems architected under the constraint that failure wasn’t acceptable - that operational lens changes what patterns become visible.
When looking at AI-assisted development, where most saw a prompting challenge, the problem looked different from this angle.
It looked like an orchestration problem.
The patterns felt familiar: autonomous agents needing state management like distributed systems do. Code generation needing deterministic workflows like CI/CD pipelines do. Multi-agent coordination needing retry logic and idempotency like infrastructure automation does. Standards enforcement needing centralized governance like Kubernetes admission controllers do.
The architecture you’re reading isn’t AI innovation. It’s operations discipline applied to autonomous code generation. Orchestration. Observability. State management. Circuit breakers. Dual enforcement. These are patterns from production infrastructure - recognized and mapped onto agents instead of services.
Here’s what that operational background revealed:
Most AI development frameworks assume unlimited retries, perfect context, and humans catching errors. That works in demos. In production - where systems fail, networks timeout, quotas hit, and unclear requirements cause rework - infrastructure thinking becomes essential. Determinism. Governance that can’t be bypassed. These aren’t optional in production systems.
The Indian tech ecosystem context made this sharper. Building for enterprises operating under RBI compliance requirements, infrastructure budget constraints, and self-hosted deployment mandates - “the AI will figure it out” isn’t an option. Systems need to be auditable, cost-controlled, and governable. That’s not a prompt engineering problem. That’s an operations architecture problem.
What follows is the architecture that emerged: a production-tested system that treats AI development as a platform, not a productivity hack. Built for enterprise constraints. Designed for regulatory environments. Tested in production with real stakes.
If you’re a founder evaluating how to scale AI-assisted development beyond a few engineers experimenting with Copilot - or an engineering leader trying to introduce autonomous agents without losing architectural control - this represents one approach that has worked in production.
The phases below map to patterns learned from building software at scale. No theory. Just what runs in production today.
Before We Start: The Most Important Thing I Learned
The bottleneck in AI-powered development is not writing code. Not anymore.
The slowest, most consequential part is clarity of intent - what the product is, who it serves, what it must never do, and what a successful outcome looks like. Agents amplify precision. But they amplify ambiguity just as effectively.
If you start building before you have this clarity, the AI will fill in the gaps. It will make choices. Some will be reasonable. Most will need to be undone. The cost of ambiguity compounds in proportion to how fast the system moves.
Keep this in mind throughout. Every phase below is ultimately in service of this insight.
Phase 0: Business and Product Clarity (Before Any Code Exists)
Most technical guides bury this. I’m putting it first because everything else depends on it.
Before agents. Before engineering standards. Before a single terminal window opens - you need structured artifacts that give the system full situational awareness. These don’t have to be perfect. But they need to exist.
For founders, this is your primary job. For engineers, this is the input you need before your systems can operate without constant human intervention.
What “Structured Artifacts” Actually Means
A Project Brief that captures: the problem being solved, who has it, what success looks like, and what constraints you’re operating under (budget, compliance, timeline). This is not a vision deck - it’s a precise definition of scope.
A Business Plan that includes revenue model, pricing assumptions, cost structure, and the key risks. This informs architectural tradeoffs. A product that must be free-tier friendly at launch is architected differently than one that serves enterprise accounts from day one.
A SWOT Analysis - not for investors, but for agents. When an AI system understands where your product is strongest and where it’s fragile, it makes better decisions about where to add defensive coding, where to invest in observability, and where to keep things simple.
A BRD/PRD with functional requirements, non-functional requirements (performance, uptime, latency), acceptance criteria, edge cases, and compliance needs. The more precisely this is written, the less the agent improvises.
Wireframes and UX Flows - screen hierarchy, navigation paths, state transitions, and especially error states. Agents build better systems when UX intent is explicit. An undefined error state in a wireframe often becomes an unhandled exception in code.
A Technical Architecture Document - system components, microservice boundaries, data flow diagrams, API contracts, auth model, and deployment topology.
A Sprint Plan - feature decomposition, dependency mapping, and priorities. Agents can execute against a sprint plan with remarkable precision when it’s well-formed.
Founder’s note: If you feel like creating these artifacts is “too much planning,” consider the alternative. An autonomous system building without them is not your co-founder - it’s a very capable contractor who’s been left alone in your office without a brief. The output will reflect that.
Phase 1: Codify Your Engineering Standards (Before the AI Sees Them)
The first mistake most developers make is jumping into AI-assisted development without first writing down how software should be built in their project.
Before modularization. Before agents. Before anything else - explicit, written engineering standards.
This includes: repository structure conventions, branching strategy (GitFlow, trunk-based), code style rules, error handling policies, logging structure, testing requirements with coverage thresholds, security constraints (input validation, secrets handling), CI/CD requirements, and deployment patterns.
When I started, all of this was inside that single CLAUDE.md. The AI followed it - technically correctly - but the approach was:
| |
The problem wasn’t correctness. It was context overload and brittleness. This is the monolithic application of AI instruction: tightly coupled, hard to evolve, impossible to reason about at scale.
For engineers: Think of this phase as writing your technical constitution. Every automated decision downstream will be governed by what you establish here. Weak standards produce an unpredictable codebase - regardless of model capability.
For founders: You don’t need to write the technical standards yourself. But you do need to insist they exist before development begins. And you need to understand that “the AI will figure it out” is not a standard.
Phase 2: Modularize the Instruction Surface (The Dev-Kit Architecture)
Once standards exist, they need to be organized.
The first real architectural improvement was splitting that 2,000-line file into domain-specific modules:
| |
Each module had a clear structure: scope definition, non-negotiable constraints, recommended patterns, example snippets, and anti-patterns.
The practical effect was immediate. Reduced context injection per task. Clear separation of concerns. Easier versioning. Selective loading depending on what task was being run.
This created what I think of as a Developer AI Dev-Kit - a modular system where:
| |
Determinism improved significantly.
There was still one structural problem: every project carried its own copy of these standards. Drift started to appear - a security rule updated in one project, forgotten in another. The solution required a different kind of architecture.
Phase 3: Centralized Standards via MCP (Single Source of Truth)
This is where things get serious - and where a brief glossary will help.
MCP stands for Model Context Protocol. It’s a standard for how AI systems request and receive information from external services. You can think of it as an API specifically designed for AI agents to query centralized knowledge.
The architectural change: instead of copying standards into each project, I built a central MCP server that all projects query at runtime. It exposes:
- Versioned engineering standards
- Architecture templates
- Code generation constraints
- Security policies
- Testing thresholds
- Lint rules
The architecture now looks like:
| |
Why this matters:
Single Source of Truth. Every project references the same standards. No drift.
Version Control of Policy. Standards can be versioned independently of any product repository. You can see exactly when a policy changed and why.
Governance Enforcement. Agents cannot bypass policies because standards are retrieved - not assumed - at runtime.
Automatic Propagation. Update a standard once; it affects every consuming project on the next run.
At this point, AI is no longer guided by embedded prompts. It is governed by externalized policy.
For teams managing multiple repositories with consistent standards requirements, this mirrors the governance patterns we use in GitLab self-hosted environments - centralized policy enforcement across distributed systems.
Access Control and Policy Governance
In enterprise environments, not all agents should access all standards. A junior-level Code Agent building a frontend component doesn’t need access to PCI-DSS compliance policies for payment processing.
MCP supports role-based access control (RBAC):
| |
Why this matters:
Principle of least privilege: Agents only see policies relevant to their domain. Reduces context size, improves response quality, prevents cross-domain confusion.
Auditability: Every MCP query is logged. You know exactly which agent accessed which policy version, when. Critical for compliance environments (SOC 2, ISO 27001, GDPR).
Separation of concerns: Security-sensitive policies (cryptographic standards, PCI-DSS requirements) can be restricted to Security and Architecture agents. Code agents receive only the implementation guidance they need.
Runtime isolation: Agents execute in isolated containers with network segmentation. Secrets injected via secure vaults, not shared environment variables. Each agent receives only the credentials required for its specific task. Audit trails log every sensitive operation for compliance verification.
Policy versioning with approval workflows:
Not all standard updates should propagate immediately. In regulated environments, policy changes require review.
Our MCP server supports:
- Draft policies: Visible only to policy authors for testing
- Review stage: Visible to Architecture team for validation
- Production policies: Live and enforced across all projects
- Deprecated policies: Marked for removal, with sunset timeline
An agent always queries the production policy version appropriate for its role. No backdoor access to draft standards. Policy changes flow through the lifecycle automatically - new services adopt updated standards, old services continue with current versions until migration is scheduled.
Founder’s analogy: Think of this as a company-wide employee handbook that every AI agent must consult before making a decision - and that can’t be ignored, because it’s loaded automatically. The difference from traditional handbooks: this one is actually enforced. And unlike human employees, agents never skip reading the handbook.
Phase 4: Deterministic Workflow Design
Before introducing agents - a pause. An important correction.
Unstructured AI task execution produces chaos. The same request produces different outputs on different days, with no clear path to improvement. What was needed was a formalized development lifecycle:
- Requirement parsing
- Architectural validation
- Code generation
- Static analysis
- Unit test generation
- Test execution
- Security scan
- Refactor loop
- Documentation update
This is the Software Development Lifecycle (SDLC), formalized for AI execution.
The key insight: deterministic pipelines beat smart agents. Process design matters more than model capability. A well-sequenced, repeatable workflow with a mediocre model will outperform a brilliant model running without structure.
Only after defining this lifecycle did agents become viable.
Phase 5: Specialized Agents Instead of One General Intelligence
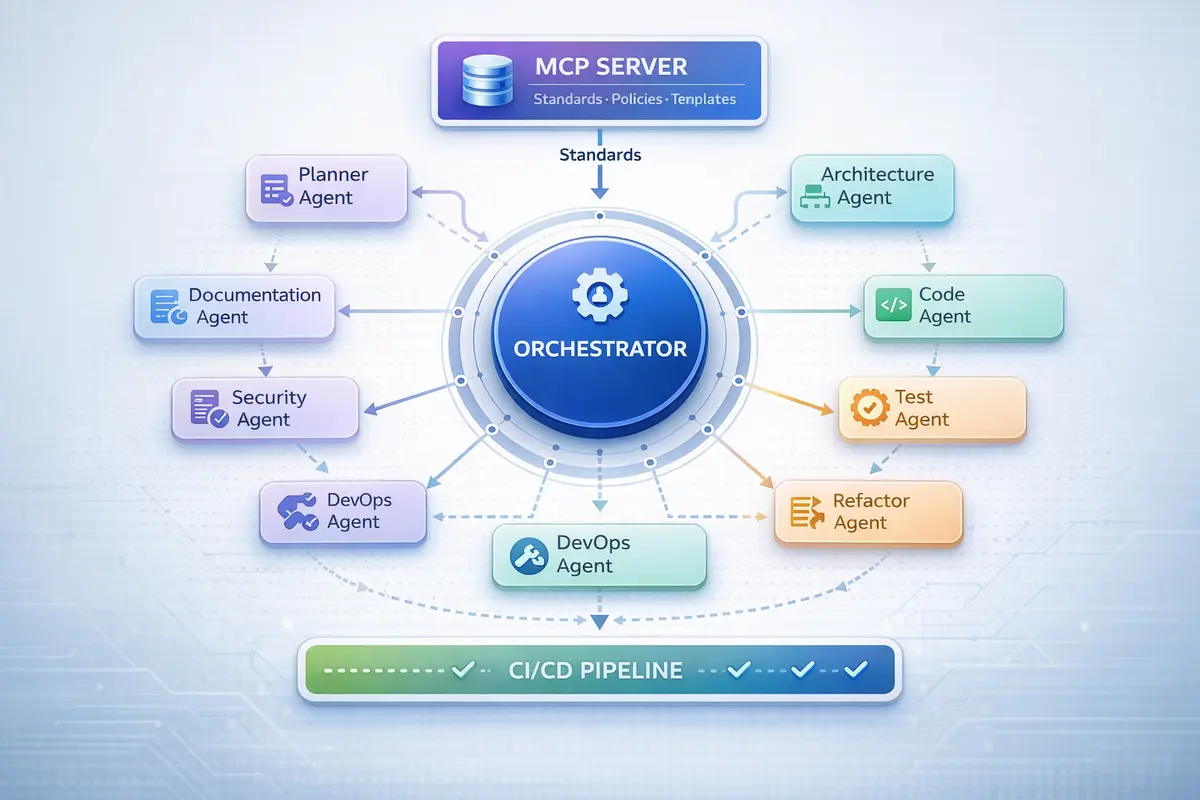
Rather than using a single AI instance for everything, I decomposed responsibilities into specialized agents - each with a defined role, clear input schema, and expected output format:
- Planner Agent - breaks features into tasks, validates scope
- Architecture Agent - validates design against MCP standards
- Code Agent - generates implementation
- Test Agent - writes unit and integration tests, enforces coverage thresholds
- Security Agent - applies SAST policies, checks dependency vulnerabilities
- Refactor Agent - optimizes code post-validation
- DevOps Agent - Dockerfiles, CI/CD, infrastructure as code
- Documentation Agent - auto-generates and maintains technical docs
This mirrors microservices architecture in software: small, specialized components are more reliable than a single general-purpose block. Each agent is predictable because it has a narrow job.
For engineers: Each agent should have: a defined input schema, expected output format, and explicit validation criteria. Without these, agents are sophisticated prompts, not components.
Phase 6: The Orchestrator - The Core Innovation
Agents without orchestration create fragmentation. You have multiple specialized systems that don’t know about each other, can’t recover from failure, and produce no consistent output.
The Orchestrator is the control plane that changes this. It:
- Maintains the task graph and controls execution order
- Handles retries when agents fail
- Validates agent outputs against MCP standards
- Fails fast when policies are violated
- Tracks state across the entire pipeline
With orchestration, the pipeline becomes:
| |
This is the critical distinction: agents are useful. Orchestration makes them production-ready.
Without it, you have enhanced automation. With it, you have a controlled development pipeline with guarantees. The orchestrator is what turns an interesting AI experiment into infrastructure you can actually rely on.
State Management and Persistence
The orchestrator doesn’t just route tasks - it maintains execution state across the entire pipeline.
What gets tracked:
- Task state: pending, in-progress, completed, failed, blocked
- Agent outputs: code artifacts, validation results, test reports, security scan findings
- Dependency graph: which tasks depend on others, what can run in parallel
- Retry attempts: how many times an agent has failed on a task, failure reasons
- Policy violations: which MCP standards were violated, where, and by which agent
Storage strategy:
For production systems, state lives in two places:
Ephemeral state (Redis or in-memory): Task queue status, current execution context, active agent sessions. Clears when the pipeline completes.
Persistent state (PostgreSQL or file-based): Completed task history, agent decision logs, artifact metadata, policy violation records. Retained for auditing and debugging.
Why this matters: when a Code Agent generates a service at 2 PM, and the Security Agent flags a vulnerability at 3 PM, the orchestrator needs to know exactly which commit, which agent version, and which MCP policy was active. Without persistent state, you’re debugging blind.
Memory and Context Strategy
Agents need memory. Not just for the current task, but across sessions.
The orchestrator manages three types of memory:
Immediate context (conversation memory): What was discussed in this execution session. The PRD details, architectural decisions made, user preferences stated. Lives in agent session memory. Cleared after task completion.
Short-term memory (project memory): Patterns from recent tasks in this project. “We’ve been using gRPC for service-to-service communication.” “Test coverage threshold was increased to 85% last week.” Stored in orchestrator state, scoped to project. Retained for 30-90 days.
Long-term memory (organizational knowledge): Historical decisions. “We deprecated REST in favor of GraphQL six months ago.” “Payment services always use PostgreSQL, not MongoDB.” Stored in MCP server as architectural principles. Retained indefinitely, versioned.
Why this architecture matters:
A Code Agent generating a new microservice queries:
- Immediate context: What does the PRD say about this service?
- Short-term memory: What patterns have we used for similar services recently?
- Long-term memory: What are our organization-wide standards for microservices?
Without this three-tier memory model, agents make inconsistent decisions. With it, they build systems that feel coherent across months of development.
Concurrency Control in Parallel Execution
When multiple features execute simultaneously, agents can collide. Two Code Agents modifying the same microservice. Overlapping database migrations. Conflicting dependency updates. Race conditions in shared repository state.
What needs protection:
Service-level locking prevents simultaneous modifications to the same codebase. Branch isolation gives each agent execution its own feature branch. Task-level coordination in the orchestrator ensures dependent tasks run sequentially, independent tasks run in parallel. File-level checksums detect conflicts before merge.
Why this matters: Without concurrency control, parallel agent execution creates merge conflicts, duplicate commits, inconsistent builds, and deployment failures. The orchestrator enforces serialization where needed, enables parallelism where safe. CI gates serve as the final checkpoint - if two agents somehow generate conflicting changes, the pipeline merge validation catches it before production.
Idempotency and Safe Retry Design
Agents fail. Networks timeout. API rate limits hit. Without idempotency, retries cause cascading problems: duplicate code generation, redundant migrations, repeated commits, exhausted quotas.
What makes retries safe:
Task execution tracked by unique identifiers. Artifact checksums verify “already generated” state. Commit deduplication prevents double-pushes. Retry counters with exponential backoff prevent runaway loops. Circuit breakers halt agents stuck in failure cycles.
Why this matters: An agent that retries a code generation task must recognize its previous output and skip regeneration - not append duplicates. An agent retrying a database migration must detect “already applied” and proceed - not fail or corrupt schema. Idempotent design turns transient failures into non-events. Without it, every retry risks making things worse.
Phase 7: CI/CD Integration - Dual Enforcement
The final structural evolution: connecting the agentic system into the CI/CD pipeline.
Standards are now enforced at two levels:
- AI generation time - via MCP policy loading
- CI validation time - via pipeline gates
Key integrations:
- Agent validation triggers on merge requests
- Test coverage gates block incomplete work
- Container builds run automatically
- Security scans execute on every push
- Merges are blocked if MCP policies fail
No agent can ship non-compliant code because the pipeline physically prevents it. This is governance as infrastructure, not governance as aspiration.
The security enforcement pattern here mirrors what we cover in Vault and Kubernetes secrets management - policies enforced at runtime by infrastructure, not by trust or documentation.
Observability: The Hidden Requirement
CI/CD integration isn’t complete without visibility into what agents are doing.
We instrument the entire pipeline with observability hooks:
Agent execution metrics: How long does each agent take? Which agents retry most frequently? What’s the pass/fail rate by agent type?
Policy violation tracking: Which MCP policies get violated most often? Are violations clustered in specific phases or specific agents?
Cost tracking: For agents using external APIs (OpenAI, Anthropic), track token usage per task, per agent, per feature. This reveals where optimization matters.
Quality metrics: Test coverage trends over time. Security scan findings by severity. Documentation completeness scores.
Ship these metrics to your observability stack. When debugging slow deployments or quality degradation, agent metrics reveal bottlenecks, retry patterns, and policy violations that would otherwise be invisible.
Without observability, agentic systems are black boxes. With it, they’re debuggable infrastructure.
Phase 7.5: Command Interface Layer (How Humans Trigger Agents)
Before Phase 8’s full autonomy, a practical question: how do humans actually invoke these agents?
The command interface layer is the bridge between human intent and agent execution. Think of it as the UX of your agentic system.
Slash Commands (CLI Wrapper)
The most immediate interface: slash commands in your development environment. Each command parses human intent, queries MCP standards, routes to the orchestrator, and streams results back. A thin CLI wrapper handles authentication and task submission.
GitLab/GitHub Integration (PR-Triggered Agents)
Agents can be triggered by repository events:
Merge request created → Architecture Agent reviews proposed changes, comments on policy violations
Push to feature branch → Test Agent generates tests for new code, commits back to branch
Issue labeled “needs-automation” → DevOps Agent generates CI/CD pipeline automatically
This turns agents into always-available code reviewers that enforce standards before human review begins.
Scheduled Execution (Cron-Triggered Maintenance)
Some agent work happens on schedule, not on-demand:
Daily: Security Agent scans all services for dependency vulnerabilities, opens issues for findings
Weekly: Documentation Agent checks if generated docs match current code, flags drift
Monthly: Refactor Agent suggests optimization opportunities based on performance metrics
These aren’t reactive tasks. They’re proactive maintenance executed by agents without human initiation.
API Interface (For External Systems)
The orchestrator exposes a REST/GraphQL API enabling: project management tools to trigger agent work when tickets are created, monitoring systems to invoke refactor agents when performance degrades, and business systems to request new services programmatically.
Why this matters: The command interface layer determines whether your agentic system feels like magic or like homework. A well-designed interface makes invoking agents natural. A poor one requires constant documentation lookups.
Phase 8: Fully Autonomous Multi-Agent Execution
When all the above layers are in place, true autonomy becomes viable.
The complete flow:
| |
At this stage, the system can:
- Create microservices with clear boundaries
- Generate API contracts
- Provision infrastructure as code
- Build Dockerfiles and CI pipelines
- Enforce coverage gates
- Validate security policies
- Generate documentation
The time compression is real. Projects that historically took 3–6 months for an MVP can now reach deployable state in days or weeks - assuming requirements clarity. Production-readiness timelines that once stretched to 9–12 months compress similarly.
But here’s the caveat you need to hear: this compression is available only when Phase 0 is done properly. Autonomous agents building against vague requirements don’t go fast. They go in the wrong direction, quickly.
Concrete Example: Building a Fintech Wallet Service
Input: PRD with wallet requirements (create, fund, transfer, history, compliance), NFRs (99.95% uptime, <200ms p95 latency, PCI-DSS considerations), architecture doc (PostgreSQL + Redis + gRPC), security policies (audit logging, rate limiting, TLS 1.3).
Autonomous execution: Planner breaks PRD into tasks. Architecture Agent validates against MCP standards, adds idempotency constraints. Code Agent generates Go service with gRPC handlers, database migrations, caching layer, rate limiting, structured logging. Test Agent creates unit and integration tests (87% coverage). Security Agent runs SAST, dependency checks, validates TLS config and secrets handling. DevOps Agent generates Dockerfile, Kubernetes manifests, CI/CD pipeline. Documentation Agent produces README, API docs, architecture decision records, runbook. Orchestrator validates all policies passed. CI/CD deploys to staging.
Output: Production-ready wallet microservice, deployed to staging, with tests, documentation, and CI/CD pipeline. Total time: 40 minutes. Traditional development: 2-3 weeks for one senior engineer.
Human contribution: Writing PRD (3 hours), reviewing architecture decisions (30 minutes), testing in staging and approving production deployment (1 hour).
This isn’t speculative. This is the workflow running in production today. The time compression is real when Phase 0 is solid.
What This Means for Indian Tech Ecosystem
A brief observation about context, because it matters.
Most AI development frameworks and tooling are built assuming:
- Access to expensive cloud compute (AWS/GCP at US pricing)
- High-bandwidth, low-latency connections
- Enterprise subscription budgets for every tool in the stack
The reality for many Indian startups and mid-sized enterprises is different:
- Infrastructure budgets measured in lakhs, not crores
- Development teams operating from tier-2 cities with variable connectivity
- Pragmatic choices between cloud and self-hosted solutions
This architecture - MCP-based standards, modular agents, orchestration - works especially well in resource-constrained environments because:
Local execution is viable. Run agents on self-hosted infrastructure. MCP servers don’t require cloud services.
Incremental adoption. Start with Phases 1-2 (standards and modules) using free tools. Add MCP and orchestration later as value becomes clear.
Reduced dependency on external APIs. Once standards are centralized via MCP, fewer calls to external AI services. Context is loaded from your own infrastructure.
Knowledge sovereignty. Your engineering standards, architecture decisions, and business logic live on infrastructure you control. Not embedded in a third-party service.
For teams operating in bandwidth-constrained or compliance-heavy environments, this matters more than the marketing materials suggest.
What Remains Human
This is the most important question - and the most honest answer I can give.
Business intent. The AI can build anything you describe precisely. It cannot decide what’s worth building.
Product judgment. What should be simple? What should be powerful? Where does user trust live in this product? These are not engineering questions.
Architecture decisions. The system can validate against your architecture. It cannot make the foundational choices about how your product is structured.
Market instincts. Why this user, this problem, this moment? That’s yours.
The AI Development Operating System is a factory. You are the architect. The factory amplifies whatever precision you bring to it - and also whatever ambiguity.
The Complete Architecture (Visual Overview)
Here’s how all the layers fit together:
| |
Key architectural principles visible in this diagram:
Top-Down Flow: Business clarity drives everything. No code generation happens without Phase 0 artifacts.
Command Layer Flexibility: Multiple ways to invoke agents (CLI, Git events, scheduled, API) - all funnel through orchestrator.
Orchestrator as Control Plane: Central point managing state, memory, and agent coordination.
MCP as Single Source of Truth: Agents query standards at runtime. No embedded policies. No drift.
Deterministic Workflow: Fixed sequence from requirements to deployment. Process beats intelligence.
Dual Enforcement: Standards enforced at generation time (MCP) AND validation time (CI/CD).
Observability as First-Class Citizen: Metrics and alerting across all layers, not bolted on later.
This isn’t a conceptual diagram. This is the production architecture running today.
The Full Evolution: A Summary
- Define business clarity - product, users, constraints, requirements
- Define engineering standards - before the AI ever sees them
- Modularize standards - one file per domain
- Externalize via MCP - centralized, versioned, enforced at runtime with RBAC
- Design deterministic workflows - sequence over intelligence
- Introduce specialized agents - narrow roles, defined schemas
- Add orchestration with state and memory - the control plane that creates reliability
- Integrate CI/CD enforcement with observability - governance as infrastructure
- Build command interface layer - CLI, Git triggers, scheduled jobs, API access
- Enable autonomous multi-agent execution - the AI factory, live
This is how AI-assisted coding evolves into an AI-powered software factory.
It is not just acceleration. It is a structural transformation of how software is built - from human-driven implementation to human-defined intent and machine-executed engineering.
That shift is the real breakthrough.
Lessons from Building This in Production
Some practical observations that don’t fit neatly into phases:
Versioning matters more than you think. When an agent makes a bad decision, you need to trace whether it was a code issue, a standard issue, or a policy version issue. We version MCP standards with semantic versioning. Breaking changes get major version bumps. This saved us during an incident where a security policy change broke three microservices - rollback was clean because the version was explicit.
Agent logs are infrastructure. Treat them like application logs. We ship agent execution logs to our observability stack. When debugging why a feature didn’t build correctly, agent decision logs are as valuable as application stack traces.
The orchestrator needs circuit breakers. An agent stuck in a retry loop will burn through API quotas and time. We added timeout policies and circuit breakers to the orchestrator. If an agent fails three times on the same task, the orchestrator halts and alerts a human.
Documentation drift is the new technical debt. Agents can generate docs automatically. But if the generated docs aren’t reviewed, they become confidently wrong. We added a documentation review gate - auto-generated docs get flagged for human review before merge.
Phase 0 is never finished. Business requirements evolve. The PRD from month 1 is stale by month 3. We schedule monthly “Phase 0 refresh” sessions where product and engineering realign on intent. The agents execute against current reality, not founding assumptions.
What This Architecture Is Not
Before expectations drift: this is not artificial general intelligence. Not a replacement for software architects. Not zero-thinking development where you describe “build me Twitter” and walk away.
This system amplifies clarity, it does not create it. Vague requirements produce vague implementations, quickly. It optimizes for speed at scale - multi-service platforms, regulated environments, consistent engineering standards across teams. For a simple CRUD app with three endpoints, traditional development is faster. The ROI appears when complexity would normally slow you down.
This is not autonomous product strategy. The AI factory builds what you specify. Market judgment, user empathy, architectural vision - those remain human. The breakthrough is not eliminating thinking. It is externalizing engineering discipline into enforceable infrastructure.
Frequently Asked Questions
What is MCP and why does it matter for AI development?
Model Context Protocol (MCP) is a standard for AI systems to query external knowledge services. It enables centralized, versioned engineering standards that agents retrieve at runtime - eliminating drift and enforcing governance across all projects. Think of it as an API specifically designed for AI agents to access your company’s engineering standards. Without MCP, you’re copying standards files into every project, and they drift. With MCP, one update propagates everywhere.
Can this work for small teams or solo developers?
Yes, but start simple. Begin with Phase 1 (written standards) and Phase 2 (modularization). Skip MCP initially - use local standards files. Add orchestration only when managing 3+ parallel features. The phases scale: solo developers benefit from deterministic workflows; larger teams need full orchestration and MCP. Don’t build the full system on day one. Evolve it as complexity demands.
How long does it take to build this infrastructure?
Phase 0 (business clarity): 1-2 weeks. Phases 1-2 (standards + modules): 1 week. Phase 3 (MCP server): 2-3 days if using existing MCP frameworks. Phases 4-6 (workflow + agents + orchestrator): 1-2 weeks. Phases 7-8 (CI/CD + autonomy): ongoing refinement. Total MVP: 4-6 weeks. But you see productivity gains after Phase 2. Don’t wait until Phase 8 to start using it.
What happens when AI-generated code doesn’t match standards?
The orchestrator validates every agent output against MCP standards before proceeding. If code violates policies, the orchestrator triggers a refactor loop or fails the task. At CI/CD time, pipeline gates provide a second enforcement layer. Non-compliant code physically cannot merge. This dual enforcement (generation-time + CI-time) is what makes the system reliable. Agents can’t ship bad code because infrastructure prevents it.
Is this overkill for simple projects?
For single-service MVPs with <5,000 lines of code: probably yes. For multi-service systems, microservice architectures, or products with compliance requirements: absolutely not. The ROI appears when complexity would normally slow you down - that’s when deterministic agentic workflows provide massive leverage. If you’re building a CRUD app with standard patterns, you don’t need this. If you’re building a fintech platform with regulatory requirements and multi-region deployment, you do.
What’s the biggest failure mode?
Vague requirements (Phase 0). Autonomous agents building against unclear product intent don’t fail slowly - they build the wrong thing, confidently. The second biggest: skipping orchestration and expecting agents to coordinate themselves. They won’t. Process design beats model intelligence. The third: not versioning MCP standards. When something breaks, you need to know which policy version caused it. Without versioning, you’re debugging in the dark.
How does this compare to GitHub Copilot or Cursor?
Copilot and Cursor are code completion tools - autocomplete on steroids. They accelerate individual developer productivity within a single editor session. This architecture is a development pipeline - it orchestrates multiple agents across an entire SDLC, from requirements to deployment. They solve different problems. Copilot helps you write a function faster. This system helps you ship a microservice architecture faster. You can use both - Copilot for in-editor acceleration, this architecture for pipeline automation.
What about costs - AI API usage must be expensive?
It depends on implementation. If every agent calls external AI APIs (OpenAI, Anthropic), costs scale with activity. Our production setup: smaller agents (test, refactor, docs) run on self-hosted open models (no API cost). Critical agents (architecture, security) use external APIs for quality. MCP server runs locally (no cost). Orchestrator is infrastructure (one-time setup). Result: API costs are ~₹15,000-25,000/month for a 5-person team shipping 3-4 features weekly. ROI is clear when you compare to hiring velocity.
What Follows
This architecture is in production. It’s not a thought experiment.
The technical implementation details - building an MCP server, designing agent schemas, orchestrator patterns, CI/CD integration code - deserve their own deep dives.
Future articles will cover:
- MCP Server Implementation Guide - building centralized standards infrastructure
- Agent Design Patterns - schemas, validation, failure modes
- Orchestrator Architecture - control planes, state management, retries
- Phase 0 Templates - BRD/PRD/SWOT formats that work with agentic systems
But this article was about the architecture. The phases. The “why” behind each layer.
Because tooling changes. Models improve. But the structure that makes autonomous systems reliable - that’s what endures.
A Final Thought
The 2,000-line CLAUDE.md wasn’t a mistake. It was evidence that something important was happening - but needed better architecture.
The same is likely true for many teams using AI to build software today. You’re seeing value. You’re moving fast. But you’re also seeing inconsistency, rework, and a nagging sense that “this should be more systematic.”
That instinct is correct.
AI-powered development isn’t about better autocomplete. It’s about externalizing process into infrastructure. Standards into policy. Sequence into guarantees.
When you do that, the system stops being a clever assistant. It becomes a development platform.
That’s the architecture worth building.
Questions? Challenges to any of this? Your own experience building agentic systems? I’m interested in how others are approaching this.